![]()
前言
花瓣网 最初是模仿国外的 Pinterest 开始做起来的图片采集分享网站,国内类似的网站有堆糖。在初期的用户积累阶段过后,花瓣网近几年开始探索其商业模式,以“图”为中心向相关领域延伸(摄影、设计、Live、电商导购等),不过不管怎么发展,用户体验还是要放在首位的,不忘初衷。
作为国内优秀的图片网站,其流畅的瀑布流图片展示、简单易用的图片采集分类方式、强大的图片采集插件,让我这个图控坚持在这里深耕多年,采集了几万张图片,骗粉几千个(欢迎关注 http://huaban.com/junlin/ )。
然而对于图控+收藏控来说,花瓣网也只是个人图库大计中的其中一环,毕竟还是有很多私图不宜光明正大放出来的,花瓣网也有违规图片检测机制,所以需要汇总花瓣网采集的图片到个人存储库中(网盘or硬盘);此为纯纯的动机,也是本文出现的原因。
技术选型
这么多图片手工一个个下载肯定是不现实的,花瓣网也没有提供批量下载画板的功能(要是有就省心了,可能是考虑到这功能开放后会影响网站运营),这样就催生了很多批量下载工具、脚本(豆皮DouP相册下载器豆瓣小组、Github 爬虫项目),基本都能很方便的下载。
本着一颗不安分喜欢折腾的心,也是出于技术学习目的,打算自己实现一个批量下载的爬虫脚本。虽然爬虫首选Python,但,作为相信着 Atwood定律 的前端er,
any application that can be written in JavaScript, will eventually be written in JavaScript. (任何能够用JavaScript实现的应用,最终都必将由JavaScript实现。) – Jeff Atwood
很自然的选择了 Node.js ,再加上越来越来流行的 TypeScript,如虎添翼,Perfect!
花瓣网技术分析
首先打开花瓣网任意一个画板,在 Chrome DevTools - Network 下观察它和服务器之前的交互。
画板资源
刷新后发现有很多网络请求,注意到最开始有个带有画板ID的 Request http://huaban.com/boards/17473820/ ,应该就是它了,服务器响应的是一个 HTML Document。
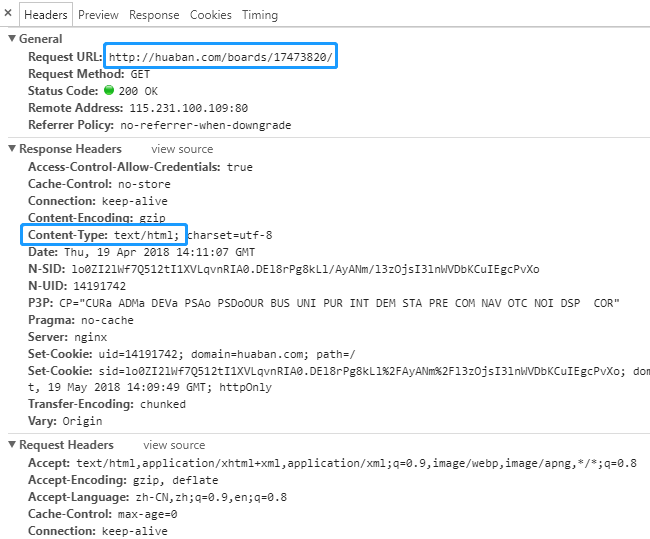
Board Data
在这个 HTML Document 中发现有个 <script> 中带有大量的 board 数据:
|
|
其中 app.page.board.pins 是一个对象数组,里面每个对象对应着画板中其中一张图片的信息,pin 代表一张图片的信息。
在网页中检查第一张图片的源 <img src="//img.hb.aicdn.com/95b6f7594128756a5fb415188cb5761c4139cebbf359b-R9Dvyn_fw236">,可以发现花瓣网图片使用了又拍云的CDN服务,第二部分即是上面的 pins[0].file.key 加上一个 _fw236 后缀;其它图片的 src 都带有这个 _fw236 后缀,暂时还不知道它的意义。
拿到了画板图片信息,到这一步就能想到可以通过爬虫来下载画板的图片。
图片懒加载
再回到画板网页上,看到页面上目前只加载了画板一部分图片,剩下的图片是通过懒加载的方式出现的(想想就知道不能一次性把所有图片都加载出来)。
拖动滚动条到底部,继续观察 Network,第一个请求 http://huaban.com/boards/17473820/?jg6ltavl&max=1584529804&limit=20&wfl=1 在画板ID后面携带了一些参数:
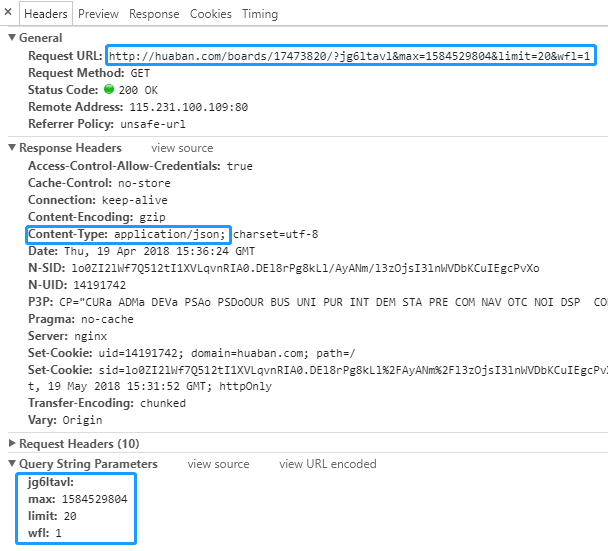
|
|
- 第一个参数是个随机字符串,最后一位按字母表顺序循环,没发现有什么意义,忽略;
- 第二个参数 max 的值是个 pin_id ;
- 第三个参数 limit 限制了服务器返回的 pin 数量;
- 第四个参数 wfl 可能是 waterfall 瀑布流的缩写,没发现有什么意义,忽略。
重点是 max 和 limit 这两个值,经过测试发现,max 是上一张图片的 pin_id,服务器按先后顺序(采集顺序)返回这张图片后面的 pin 数据;
而 limit 告诉服务器返回多少个 pin 数据。后面测出服务器对 limit 做了最大值校验,最大是 100,即一次最多只能加载100张图片数据。
到了现在可以开始写爬虫模拟上面的操作了。
Node 爬虫实现
使用 Node.js 实现命令行程序,提供两种方式下载图片:
- 输入画板ID下载该画板的所有图片
- 输入用户ID下载该用户所有自建画板的图片(不包括收藏的画板)
输入画板ID下载该画板的所有图片
-
在命令行中跟用户交互,使用 Node
readlineAPI实现在stdin/stdout读取输入和显示输出:1 2 3 4 5 6 7import readline from 'readline' const rl: readline.ReadLine = readline.createInterface({ input: process.stdin, output: process.stdout, }) rl.question('画板ID:', boardId => {}) -
首先根据画板ID获取
board数据,然后获取到board中所有的pins数据,最后根据每个pin数据下载图片到本地目录中,中间向命令行中输出一些提示:1 2 3 4 5 6 7 8async function downloadSingleBoard(boardId: string): Promise<void> { console.time('Total time') const board = await getBoardInfo(boardId) console.log('\n开始下载画板 %s - %s,图片数量:%d', boardId, board.title, board.pin_count) await getPinsAndDownload(board) outputResult() } -
根据画板ID获取
board数据。为了使用 ES7 的async/await,引入了promisify的 request 库1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20import rp from 'request-promise' async function getBoardInfo(boardId: string): Promise<IBoard> { const response: { err?: number board: IBoard } = await rp({ uri: `${huabanDomain}/boards/${boardId}/`, headers: jsonRequestHeader, qs: { limit: 1, }, json: true, }) if (response.err === 404) { throw new Error('画板不存在!') } return response.board } -
获取
pins数据然后下载图片,输出结果。其中在获取pins数据的时候发现有些画板无法获取全部的pins数据,造成画板图片下载不全(暂时还不清楚原因)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19async function getPinsAndDownload(board: IBoard): Promise<void> { const boardPins = await getPins(board.board_id) // TODO: 有些画板获取的pins数据不全? const missedPinsCount = board.pin_count - boardPins.length const boardPath = `${downloadPath}/${board.board_id} - ${board.title}` fs.emptyDirSync(boardPath) const downloadCount: number = await downloadImage(boardPins, boardPath) const failedCount: number = board.pin_count - downloadCount - missedPinsCount totalDownload += downloadCount console.log( `Done. 成功 %d 个${failedCount ? `,失败 \x1b[31m${failedCount}\x1b[0m个` : ''}${ missedPinsCount ? `,丢失 \x1b[31m${missedPinsCount}\x1b[0m 个` : '' }`, downloadCount, ) } -
获取画板中全部pins(图片)数据。有个关键的点,请求头部中如果不加上
'X-Requested-With': 'XMLHttpRequest',服务器返回的是包含json的HMLT Document,而不是单纯的json数据。我看到有些脚本没有注意到这点,就需要用正则截取HTML中的json,多走了一步弯路(我也是从弯路走过来的,这里提醒后面的读者)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40// 关键头部,添加该项后服务器只会返回json数据,而不是包含json的HTML const jsonRequestHeader = { Accept: 'application/json', 'X-Requested-With': 'XMLHttpRequest', } async function getPins(boardId: string): Promise<IPin[]> { const allPins: IPin[] = [] async function loadPins(lastPinId: string = ''): Promise<void> { // limit 查询参数限制获取的pin数量,最大100,默认20 const response = await rp({ uri: `${huabanDomain}/boards/${boardId}/`, qs: { limit: 100, max: lastPinId, }, headers: jsonRequestHeader, json: true, }) const board = response.board // if (response.headers['content-type']!.includes('text/html')) { // // 匹配 boards json 串 // const boardJson: string = /app\.page\["board"\]\s=\s({.*});/.exec(response)![1] // board = JSON.parse(boardJson) // } allPins.push(...board.pins) // 当此次获取的pins为空或者全部pins已获取完,则返回 const pinsChunkLength: number = board.pins.length if (pinsChunkLength && allPins.length < board.pin_count) { // 用最后一个pin id作为下一次请求的max值,表示获取该pin后面的pins await loadPins(board.pins[pinsChunkLength - 1].pin_id) } } await loadPins() return allPins } -
根据
pins下载图片。这里引入了async异步库来控制同一时间的下载并发数,否则并发过高Node会失去响应;下载失败的图片还会重试一次1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55async function downloadImage(allPins: IPin[], boardPath: string): Promise<number> { let downloadCount: number = 0 const errorImageUrl: Array<{ url: string; path: string }> = [] // 重试下载失败的图片 function retry() { for (const image of errorImageUrl) { rp({ uri: image.url, timeout: 20 * 1000, encoding: null, // make response a Buffer to write image correctly }).pipe( fs.createWriteStream(image.path).on('finish', () => { totalDownload++ console.log('\x1b[32m Retry ok! \x1b[0m %s', image.url) }), ) } } function download(pin: IPin, cb: () => void): void { const imageUrl: string = `${imageServer}/${pin.file.key}_fw658` const imageName: string = `${pin.pin_id}${imagesTypes[pin.file.type] || '.jpg'}` rp({ uri: imageUrl, timeout: 20 * 1000, encoding: null, // make response a Buffer to write image correctly }) .then(data => { downloadCount++ fs.writeFile(`${boardPath}/${imageName}`, data, error => { error && console.error('\x1b[31m%s\x1b[0m%s', error.message, imageUrl) }) }) .catch(error => { console.error('\x1b[31m%s %s.\x1b[0m %s', 'Download image failed.', error.message, imageUrl) errorImageUrl.push({ url: imageUrl, path: `${boardPath}/${imageName}` }) }) .finally(cb) } // async控制并发下载数,否则并发数太高Node会失去响应 return new Promise<number>(resolve => { // 同一时间最多有10个(不能太高)并发请求 async.eachLimit(allPins, 10, download, (error: IError | undefined) => { if (error) { throw error } errorImageUrl.length && retry() resolve(downloadCount) }) }) } -
下载的图片会保存在默认
images目录或者用户输入的指定目录中,下载速度平均 5 张/秒
输入用户ID下载该用户所有自建画板的图片(不包括收藏的画板)
-
命令行中输入用户ID
1rl.question('请输入地址栏中的用户名:', username => {}) -
首先获取到该用户的所有画板数据,然后顺序下载每个画板中的图片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19async function downloadBoardsOfUser(username: string): Promise<void> { console.time('Total time') const userBoards: IBoard[] = await getUserBoards(username) console.log('\n用户 [%s] 画板数量:%d', username, userBoards.length) // 顺序下载画板,并行下载会失控 for (const board of userBoards) { console.log( '\n开始下载画板:[%s - %s],图片数量:%d', board.board_id, board.title, board.pin_count, ) await getPinsAndDownload(board) } outputResult() } -
获取用户画板。用户画板也使用了懒加载方式,所以也需要去循环获取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36async function getUserBoards(username: string): Promise<IBoard[]> { const allUserBoards: IBoard[] = [] async function getBoards(lastBoardId?: string): Promise<void> { const response: { err?: number user?: IUser } = await rp({ uri: `${huabanDomain}/${username}/`, qs: { limit: 100, max: lastBoardId, }, headers: jsonRequestHeader, json: true, }) if (response.err === 404) { throw new Error('用户不存在!') } else if (!response.user!.board_count) { throw new Error('用户没有画板!') } const user: IUser = response.user! const requestUserBoardsCount = user.boards.length allUserBoards.push(...user.boards) // 获取所有画板数据 if (requestUserBoardsCount && allUserBoards.length < user.board_count) { await getBoards(user.boards[requestUserBoardsCount - 1].board_id) } } await getBoards() return allUserBoards } -
后面步骤跟方式一相同,这里只是使用
for循环下载多个画板图片
总结
这次爬虫几乎没有遇到服务器的反抗,花瓣网没有做反爬虫检测,最基本的 User-Agent 都不需要伪装,很适合爬虫初学者拿来练手;这种开放共享的精神值得表扬👍。
遗留下了有些画板 pins 数据不全的问题,等待有缘再解决。
Github Project
项目引入了 TSLint、Prettier 来规范代码风格,用 ts-node 来执行 .ts 程序;
代码放到Github上了 ➡ Jancat/huaban-crawl
Enjoy the pictures ~